
Orthogonalization

- Importance of having a single real number evaluation metric: F1 score for Precision and Recall, Satisficing and optimizing metrics
- Comparing with human level performance


- As we approach human level performance, it is harder to detect which one of bias/variance needs improvement
- Human level performance as a proxy for Bayes error
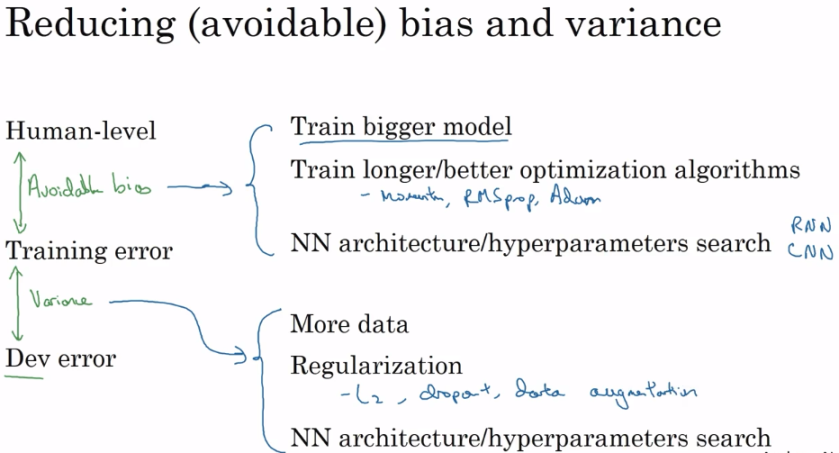
- Setting up training, dev and test sets properly
- Always make sets come from same distribution
- Size of test set should be big enough for confidence in final performance of system
- Changing evaluation metrics and shifting targets in between project
- Specifically giving more weight to extreme wrong examples

- If doing well on current metric + dev/test set does not correspond to doing well on final application, we should change the metric or the dev/test set
Error Analysis
- Manually determining why our model is failing by analyzing wrong inferences.
- Determine category based error rate to focus improvements.

- Random errors vs Systematic errors in training set
- Important to consider examples which we got wrong and right too
- Setup train/dev/test sets and build your first system quickly and then iterate according to Bias/Variance and Error Analysis
Mismatched training and dev/test sets
- Data set must reflect the target to hit, don’t target PC when user is on mobile
- Set training set as (M+m), dev/test set as (m) – dev set might be much harder
- Training-dev set = Representative of training set to determine if network is flawed [high bias / variance] or (dev) data is too hard to process [data mismatch problem]
- Fundamental take away is that performance must be compared across data sets coming from same distribution
- Transfer learning as sober first, drunk later
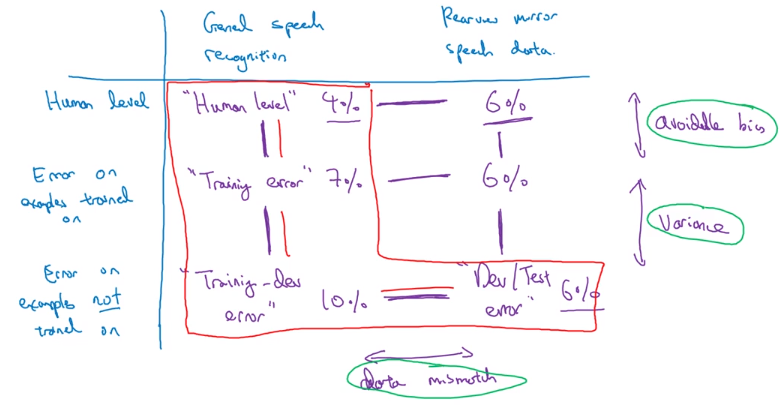
Addressing data mismatch
- When you train on perfect pictures and dev/test on blurry pictures and your model performs very poorly, rather than when your data labels are wrong
- Artificial data synthesis
- How distribution of data in training and dev set differs, make training data more similar to dev/test sets
- Careful about over-fitting to noise(just 1 hour of noise)
Transfer Learning
- When we have
- Lot of data for original problem A and less data for target problem B
- Same input data for both problems
- Low level features from A and B are preferably common
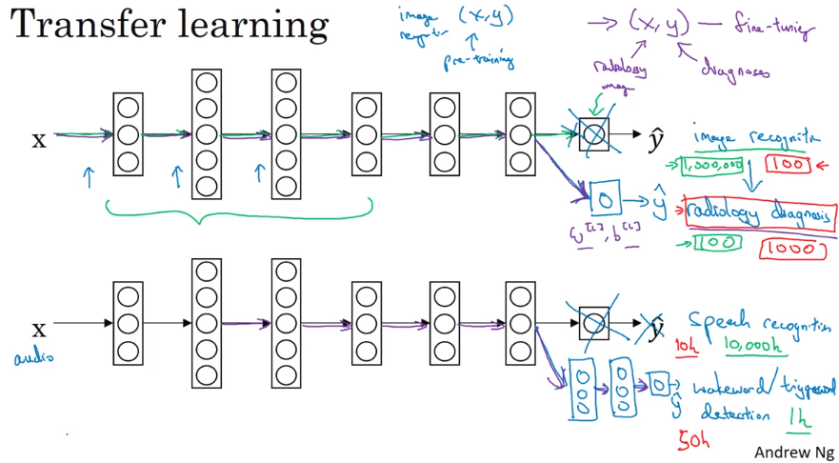
- Deleting final layer, expanding new network, deciding to train initial layers or not and how deep to keep level of training
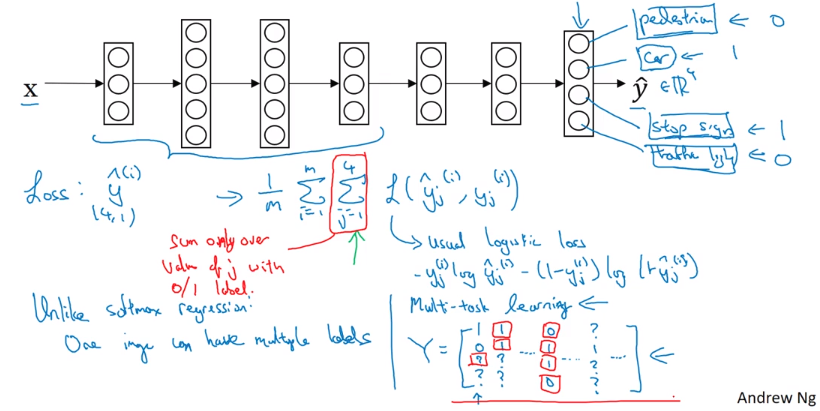
Multi-task learning
- Training one network to classify 4 things > Training 4 networks to classify 1 thing

End-to-end Learning
- Replacing multiple stages of learning with a single network. Requires a very large amount of data to compete with the traditional pipeline approach.
- A network learns from the data, and from the hand designed components(which reflect the human knowledge)
- Key question to ask is if we have enough data to learn a function of the complexity needed to map x to y?
